
逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,由于分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。纯文本意味着该文件是一个字符序列,不含必须像二进制数字那样被解读的数据。CSV文件由任意数目的记录组成,记录间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其它字符或字符串,最常见的是逗号或制表符。常日,所有记录都有完备相同的字段序列。常日都是纯文本文件。建议利用WORDPAD或是记事本来开启,再则先另存新档后用EXCEL开启,也是方法之一。
大略理解便是,每一行代表一个数据记录,每个字段之间用逗号进行分隔。字段可以包含文本、数字或日期等各种类型的文本数据。

下面给一个数据示例:
姓名,年事,性别张三,25,男李四,30,男王五,28,男
这样的一个文件,你把它的后缀名改成csv,就可以用excel打开了,展示的效果基本和excel文件同等,当然也可以用各种编辑器打开编辑。那么在python中如何读写csv文件呢?
方案一:直策应用文本文件读写的办法
既然csv是纯文本形式存储的,那就可以按照文本文件的办法进行读写,只要知道它的规则:每一行代表一个数据记录,每个字段之间用逗号进行分隔。实在也可以用其他符号,比如分号,但是既然叫逗号分隔符,而且大多数人都是用逗号,那么我们这里最好是随大流就行了。
with open('demo.csv', 'w', encoding='utf8') as file: file.write('姓名,年事,性别\n') file.write('张三,25,男\n') file.write('李四,30,男\n') file.write('王五,28,男\n')with open('demo.csv', 'r', encoding='utf8') as file: for line in file: print(line, end='') fields = line.strip('\n').split(',') print(fields)
方案二:标准库中的csv模块,利用个中的render和writer完成csv的读写
在上面的例子中可以瞥见,直接用文本的办法读写,当你须要读取的字段的时候须要利用strip和split方法进行分割,写入的时候须要将数据字段拼接成一个大的字符串,略选麻烦,实在csv文件的读取和写入可以通过内置的csv模块轻松实现。
csv.reader(csvfile, dialect='excel', fmtparams)csv.writer(csvfile, dialect='excel', fmtparams)csvfile 可以是任何工具,只要这个工具支持 iterator 协议并在每次调用 __next__() 方法时都返回字符串,文件工具 和列表工具均适用。dialect 是用于不同的 CSV 变种的特定参数组fmtparams 可以覆写当前变种格式中的单个格式设置
import csvwith open('demo.csv', 'r', encoding='utf8') as file: render = csv.reader(file) print(next(render)) #['姓名', '年事', '性别'] print(next(render)) #['张三', '25', '男'] # 也可以循环获取 for data in render: print(data)
import csvdata = [ ['姓名', '年事', '性别'], ['张三', '25', '男'], ['李四', '30', '男'], ['王五', '28', '男1'],]with open('demo.csv', 'w', encoding='utf8') as file: writer = csv.writer(file) # 逐行写入 for row in data: writer.writerow(row)with open('demo.csv', 'w', encoding='utf8') as file: writer = csv.writer(file) # 多行一起写入 writer.writerows(data)
我们看一下结果文件,创造空了一行,怎么删除这一行呢,就须要在open的时候设置newline='',这样就删除了空行。
with open('demo.csv', 'w', encoding='utf8', newline='') as file: writer = csv.writer(file) writer.writerows(data)
方案三:利用csv.DictReader和csv.DictWriter读写字典文件
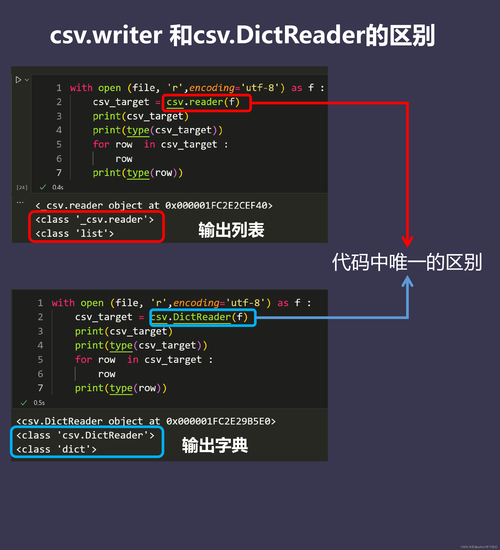
按照上面方案二的做法,比方案一要方便很多了,不须要自己手动去做字符串的拼接和分割了,但是它读取和写入的数据构造都是列表,须要通过索引来访问,而有时我们的数据是字典形式,具有明确标题行。
render和writer实在是更加灵巧的办法,由于它不依赖于标题行的存在;而DictReader和DictWriter则更适用于那些具有明确标题行的CSV文件。DictReader假设CSV文件的第一行是标题行,并据此创建字典的键。如果CSV文件没有标题行,你须要供应fieldnames参数。
import csvwith open('demo.csv', mode='r', encoding='utf8', newline='') as file: reader = csv.DictReader(file) for row in reader: print(row) print(row['姓名'])# OrderedDict([('姓名', '张三'), ('年事', '25'), ('性别', '男')])# OrderedDict([('姓名', '李四'), ('年事', '30'), ('性别', '男')])# OrderedDict([('姓名', '王五'), ('年事', '28'), ('性别', '男')])# 如果文件中没有标题行,根据你的CSV文件自定义列名fieldnames = ['姓名', '年事', '性别']with open('demo.csv', mode='r', encoding='utf8', newline='') as file: reader = csv.DictReader(file, fieldnames=fieldnames) for row in reader: print(row) print(row['姓名'])# 结果是一样的
再看一下写入
import csvfieldnames = ['姓名', '年事', '性别']with open('demo.csv', mode='w', encoding='utf8', newline='') as file: writer = csv.DictWriter(file, fieldnames=fieldnames) writer.writeheader() writer.writerow({'姓名': '111', '年事': '222', '性别': '333'})如何解析字段中包含逗号(,)的csv文件
再思考一个问题,既然是逗号分隔符,那如果我们的原始数据中就含有逗号呢,这种数据怎么处理?实在不用担心,面对这种问题无须分外处理,还是可以利用标准库中的方法直接读写,会自动处理:
writer.writerow({'姓名': '11,1', '年事': '222', '性别': '333'})# 结果# 姓名,年事,性别# "11,1",222,333
我们看到写入的结果中,数据被双引号包围起来了,避免产生歧义。
但是如果我们是利用第一种办法,直接用文本的办法读写csv文件的时候,这种问题的处理是非常麻烦的,以是利用的时候要慎重。















