
发量稀少的口试官皱着眉头在浏览后端君的简历,正在我忐忑不定的时候,他开口了:“我看你简历上写着熟习Java凑集,那你一定知道HashMap吧?”
我点点头,略懂。

那你先来大略先容一下你理解的HashMap,你可以把你知道的都说一下。
这么牛?那我可不客气了,HashMap我可是看过源码的!
轻微梳理了一下,后端君开始了。
1. HashMap简述
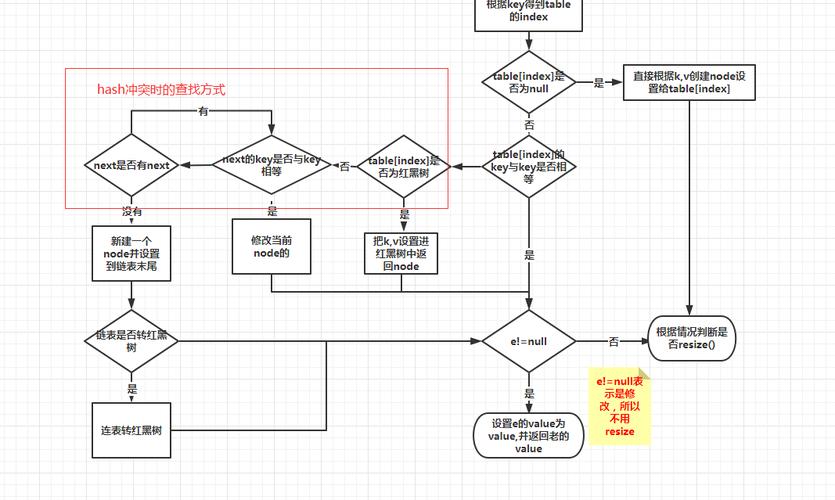
HashMap是一个基于哈希表实现的无序的key-value容器,它键和值都许可设置为null,但是它是线程不屈安的,同时在默认情形下如果HashMap元素超过默认容量的0.75时会进行扩容,将容量扩大为原来的两倍。
1.1 HashMap的底层数据构造在JDK1.7以前HashMap底层是数组和链表实现的,但是为了防止同一个数组下标中的链表过于长导致查询效率过低的情形,从JDK1.8开始在HashMap容量大于64且链表长度大于8时会将链表转化为红黑树。
HashMap中每一个元素都以一个Node节点的形式存放在数组中。
HashMap底层构造
static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next; // ...}
hash属性是键的哈希值,key属性存放的是键,value属性存放的是值。
还有一个next属性,便是当两个key的哈希值相同时,这两个元素会被放在数组的同一个下标位置中,通过next属性指定一下个Node工具,从而会形成一个链表。
1.2 哈希碰撞HashMap的底层数据构造首先是一个Node类型的数组,一个Node节点存放在数组中的位置(即数组下标)是由该Node节点key属性的哈希值(也便是hash属性)确定的,但是这就可能产生一种分外情形——不同Node节点的哈希值相同。
如果存在两个Node节点的hash属性相同,那么它们都会存放在数组下标为hash的位置,同时会通过Node节点的next属性将这两个节点连接在一起,形成一个链表,这就办理了哈希冲突的问题。
举个例子,当我在Map中添加一个键为Java值为No1的元素时,Java字符串会通过hash方法来打算哈希值。假设Java字符串的哈希值为1,那么此时HashMap的构培养是下面这样。
放入键Java后的HashMap
假设这时再放入一个键为PHP值为No2的元素,刚好很不巧假设PHP作为键的哈希值结果也是1,那么这个Node节点也会放在数组下标为1的位置上,同时与Java键形成一个链表,如下图所示。
JDK1.7中是头插法,会引起去世循环,在JDK1.8中改为利用尾插法。
放入键PHP后的HashMap
但是如果发生大量哈希值相同的分外情形,导致链表很长,就会严重影响HashMap的性能,由于链表的查询效率须要遍历所有Node节点。
于是在JDK1.8引入了红黑树,当链表的长度大于8,且HashMap的容量大于64的时候,就会将链表转化为红黑树。
// JDK1.8 HashMap#putValfinal V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { // 省略 // binCount 是该链表的长度计数器,当链表长度大于即是8时,实行树化方法 // TREEIFY_THRESHOLD = 8 if (binCount >= TREEIFY_THRESHOLD - 1) treeifyBin(tab, hash); // 省略}// HashMap#treeifyBin final void treeifyBin(Node<K,V>[] tab, int hash) { int n, index; Node<K,V> e; // MIN_TREEIFY_CAPACITY=64 // 若 HashMap 的大小小于64,仅扩容,不会转化为红黑树 if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY) resize(); else if ((e = tab[index = (n - 1) & hash]) != null) { // 代码省略... }}1.3 如何打算键的哈希值
“你刚刚一贯在说键的哈希值,那它到底是怎么打算的你理解吗?”口试官再次提问。这是要问源码了,作为自称看过源码的人,后端君当然不会落下hash函数,于是胸有成竹。
当一个键值对被放入HashMap时,会通过HashMap#hash(Object key)方法来打算该键的哈希值,作为它存放在HashMap数组中的索引下标值,hash方法的源码如下所示。
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}
如果键为null的元素,它会被放在HashMap数组下标为0的位置。
然后便是键不为null的情形。
h被赋值为键的哈希值进行h >>> 16运算将上述两步的结果进行^运算作为一个在大学时打算机组成事理差点挂科的差等生,后端君对付位运算符实在是有些发憷的,幸而得到搜索引擎老师的教导,才搞明白了上述两个位运算符的意义。
>>>符号表示无符号右移,右移后高位补0^是异或运算符,当两者不同时结果为1,相同时结果为0假设h=15,我们来打算一下hash方法的结果,先把15转化为二进制,也便是0000 1111。
h >>> 16的结果便是在15的32位二进制中取高半区,也便是0000 0000 0000 0000,末了对这两者做异或运算。
运算结果
以是终极h=15的键值对将被存放在HashMap数组下标为15的位置。
上面这段hash方法有一个专业术语叫做扰动函数,它的浸染便是让元素充分的散列,减少发生哈希碰撞的可能性。
1.4 为什么HashMap是线程不屈安的"看来你对HashMap还是有些理解的,那你知道为什么HashMap是线程不屈安的吗?"
线程不屈安?那当然是多线程情形下没有考虑并发的情形了。如果口试的时候这么答,那基本是凉凉了。
后端君在CSDN上找到一篇比较全面的回答:JDK1.7和JDK1.8中HashMap为什么是线程不屈安的?(https://blog.csdn.net/swpu_ocean/article/details/88917958),写的很详细,建议大家可以去看一下。
对付这个问题后端君就不再赘述啦。
总结一下:
在JDK1.7中,并发实行扩容操作时会造成环形链和数据丢失的情形在JDK1.8中,并发实行put操作时会发生数据覆盖的情形2. 红黑树
“既然HashMap在扩容时会将链表树化,那再来说说红黑树吧,你对红黑树有什么理解?”口试官脸上毫无表情,稳稳地再次抛出一个包袱。
红黑树是一棵分外的二叉搜索树,除了根节点外,每个非根节点有且只有一个父节点,对付一个节点来说,它的左子树上所有节点的值都小于即是根节点的值,它的右子树上的值都大于即是根节点的值,同时从任一节点到其每个叶子的所有路径都包含相同数目的玄色节点。
基于红黑树这样的构造特性,它的韶光繁芜度是O(logn),以是会比链表的O(N)快,这也便是JDK1.8引入红黑树的缘故原由。
红黑树
“那HashMap的红黑树是如何进行掩护的呢?比如我插入一个数,如何担保这棵树还是一个红黑树?”
这……后端君只知道在HashMap会通过左旋右旋来掩护一棵红黑树,详细的逻辑……还真不知道,于是只能如实回答。
3. 加载因子
“没紧要”,口试官终于有表情了,他彷佛觉得挺满意似的在笑?“那你之条件到过HashMap在进行扩容的时候有一定的条件,便是元素超过默认容量的0.75,那为什么这个值被定为0.75呢?”
这个0.75是HashMap的加载因子属性,它是用来进行扩容判断的。
假设加载因子是0.5,HashMap初始化容量是16,当HashMap中有16 0.5=8个元素时,HashMap就会进行扩容操作。
而HashMap中加载因子为0.75,是考虑到了性能和容量的平衡。
由加载因子的定义,可以知道它的取值范围是(0, 1]。
如果加载因子过小,那么扩容门槛低,扩容频繁,这虽然能使元素存储得更稀疏,有效避免了哈希冲突发生,同时操作性能较高,但是会占用更多的空间。如果加载因子过大,那么扩容门槛高,扩容不频繁,虽然占用的空间降落了,但是这会导致元素存储密集,发生哈希冲突的概率大大提高,从而导致存储元素的数据构造更加繁芜(用于办理哈希冲突),终极导致操作性能降落。还有一个成分是为了提升扩容效率。由于HashMap的容量(size属性,布局函数中的initialCapacity变量)有一个哀求:它一定是2的幂。以是加载因子选择了0.75就可以担保它与容量的乘积为整数。// 布局函数public HashMap(int initialCapacity, float loadFactor) { // …… this.loadFactor = loadFactor;// 加载因子 this.threshold = tableSizeFor(initialCapacity);}/ 返回2的幂 Returns a power of two size for the given target capacity. MAXIMUM_CAPACITY = 1 << 30 /static final int tableSizeFor(int cap) { int n = cap - 1; n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;}4. HashMap容量
HashMap的默认初始容量是16,而每次扩容是扩容为原来的2倍。这里的16和2倍就担保了HashMap的容量是2的n次幂,这样设计的缘故原由是什么呢?
缘故原由一:与运算高效与运算&,基于二进制数值,同时为1结果为1,否则便是0。如1&1=1,1&0=0,0&0=0。利用与运算的缘故原由便是对付打算机来说,与运算十分高效。
缘故原由二:有利于元素充分散列,减少 Hash 碰撞在给HashMap添加元素的putVal函数中,有这样一段代码:
// n为容量,hash为该元素的hash值if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null);
它会在添加元素时,通过i = (n - 1) & hash打算该元素在HashMap中的位置。
当 HashMap 的容量为 2 的 n 次幂时,他的二进制值是100000……(n个0),以是n-1的值便是011111……(n个1),这样的话(n - 1) & hash的值才能够充分散列。
举个例子,假设容量为16,现在有哈希值为1111,1110,1011,1001四种将被添加,它们与n-1(15的二进制=01111)的哈希值分别为1111、1110、1110、1011,都不相同。
而假设容量不为2的n次幂,假设为10,那么它与上述四个哈希值进行与运算的结果分别是:0101、0100、0001、0001。
可以看到后两个值发生了碰撞,从中可以看出,非2的n次幂会加大哈希碰撞的概率。以是HashMap的容量设置为2的n次幂有利于元素的充分散列。
5. 去世循环上文在说到为什么HashMap是线程不屈安的的时候提到过在JDK1.7中由于哈希碰撞,在同一个数组下标中进行链表元素的新增时是用头插法,会导致去世循环,而在JDK1.8中改为利用尾插法,避免了去世循环的情形的发生。
关于口试我还通过一些渠道整理了大厂真实口试紧张有:蚂蚁金服、拼多多、阿里云、百度、唯品会、携程、丰巢科技、乐信、软通动力、OPPO、银盛支付、中国安然等初,中级,高等Java口试题凑集,附带超详细答案,希望能帮助到大家。资料获取办法:转发+关注,然后私信【电子书】即可免费领取~
还有专门针对JVM、SPringBoot、SpringCloud、数据库、Linux、缓存、中间件、源码等干系口试题。
领取步骤1、关注,转发2、私信发送:电子书















