
特点
HashMap底层是由哈希表构造组成的,实在便是“数组+链表”的组合体,数组是HashMap的主体构造,链表则紧张是为理解决哈希值冲突而存在的分支构造。正由于这样分外的存储构造,HashMap凑集对付元素的增、删、改、查操作表现出的效率都比较高。

构造
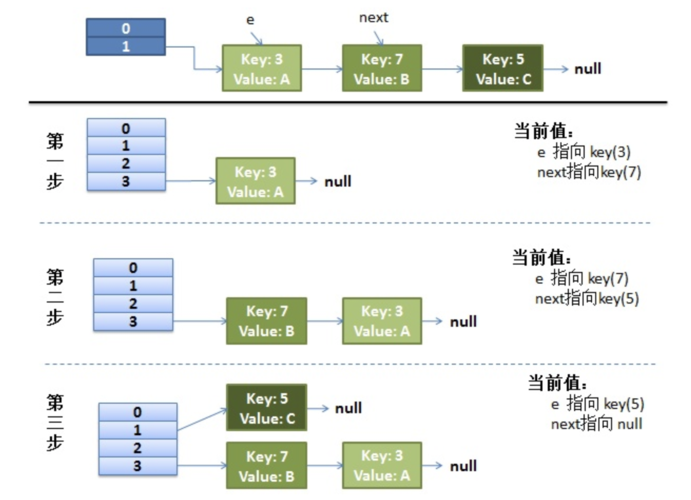
在java1.8往后采取数组+链表+红黑树的形势来进行存储,通过散列映射来存储键值对,如下图:
在初始化时将会给定默认容量为16对key的hashcode进行一个取模操作得到数组下标数组存储的是一个单链表数组下标相同将会被放在同一个链表中进行存储元素是无序排列的链表超过一定长度(TREEIFY_THRESHOLD=8)会转化为红黑树红黑树在知足一定条件会再次退回链表2 HashMap的定义HashMap的布局函数
HashMap共有4个布局函数,如下:
// 默认布局函数。HashMap()// 指定“容量大小”的布局函数HashMap(int capacity)// 指定“容量大小”和“加载因子”的布局函数HashMap(int capacity, float loadFactor)// 包含“子Map”的布局函数HashMap(Map<? extends K, ? extends V> map)3 HashMap的利用3.1 HashMap的基本用法
创建HashMap工具 要创建一个HashMap工具,您可以利用如下的办法:
import java.util.HashMap;import java.util.Map;public class Main { public static void main(String[] args) { // 创建一个HashMap工具 Map<String, Integer> hashMap = new HashMap<>(); }}
添加键值对 您可以利用put方法来向HashMap中添加键值对:
hashMap.put("apple", 1);hashMap.put("banana", 2);hashMap.put("cherry", 3);
获取值 要从HashMap中获取值,可以利用get方法,并传入键:
int value = hashMap.get("banana"); // 获取键"banana"对应的值,此时value为2
删除键值对 要删除HashMap中的键值对,可以利用remove方法:
hashMap.remove("apple"); // 删除键"apple"对应的键值对
遍历HashMap 遍历HashMap可以利用不同的方法,最常见的是利用forEach方法:
hashMap.forEach((key, value) -> { System.out.println(key + ": " + value);});3.2 HashMap的高等用法
处理碰撞 HashMap在处理哈希碰撞(即两个不同的键映射到了同一个哈希桶中)时,利用了链表和红黑树构造来存储键值对。这使得HashMap在大多数情形下都能供应O(1)的性能。
容量和负载因子 HashMap有两个主要的参数,分别是容量(capacity)和负载因子(load factor)。容量是哈希表中桶的数量,而负载因子是桶的添补程度。当HashMap中的元素数量超过容量与负载因子的乘积时,哈希表会进行扩容,以保持性能。
Map<String, Integer> hashMap = new HashMap<>(16, 0.75f);
遍历键凑集或值凑集 除了利用forEach方法遍历键值对外,您还可以利用keySet和values方法来分别获取键的凑集和值的凑集,并进行遍历:
Set<String> keys = hashMap.keySet(); // 获取所有键的凑集Collection<Integer> values = hashMap.values(); // 获取所有值的凑集for (String key : keys) { System.out.println(key);}for (int value : values) { System.out.println(value);}
替代默认值 当从HashMap中获取值时,如果键不存在,常日会返回null。如果您希望在键不存在时返回一个默认值,可以利用getOrDefault方法:
int value = hashMap.getOrDefault("orange", 0); // 如果键"orange"不存在,返回默认值0
合并操作 您可以利用merge方法来合并两个HashMap:
Map<String, Integer> anotherMap = new HashMap<>();anotherMap.put("apple", 5);anotherMap.put("banana", 6);anotherMap.forEach((key, value) -> { hashMap.merge(key, value, (oldValue, newValue) -> oldValue + newValue);});
这将合并两个HashMap,如果键相同,则将值相加。
3.3 更多操作当涉及到HashMap的更多操作时,有一些主要的观点和方法可以帮助您更灵巧地处理数据。以下是一些HashMap的更多操作:
获取HashMap的大小 要获取HashMap中键值对的数量,可以利用size方法:int size = hashMap.size();
这将返回HashMap中键值对的数量。
判断HashMap是否为空 您可以利用isEmpty方法来检讨HashMap是否为空:boolean isEmpty = hashMap.isEmpty();
如果HashMap为空,将返回true,否则返回false。
更换值 如果要更换HashMap中的值,可以利用replace方法:hashMap.replace("apple", 4); // 将键"apple"对应的值更换为4清空HashMap 要清空HashMap中的所有键值对,可以利用clear方法:
hashMap.clear(); // 清空HashMap判断是否包含键或值 您可以利用containsKey方法来检讨HashMap是否包含特定键:
boolean containsKey = hashMap.containsKey("apple"); // 检讨是否包含键"apple"
同样地,您可以利用containsValue方法来检讨HashMap是否包含特定值:
boolean containsValue = hashMap.containsValue(2); // 检讨是否包含值2复制HashMap 如果须要创建一个与现有HashMap相同的副本,可以利用clone方法:
Map<String, Integer> copyHashMap = new HashMap<>(hashMap);
这将创建一个与hashMap相同的新HashMap。
获取键值对的凑集 除了利用keySet和values方法获取键凑集和值凑集外,您还可以利用entrySet方法来获取键值对的凑集:Set<Map.Entry<String, Integer>> entrySet = hashMap.entrySet();for (Map.Entry<String, Integer> entry : entrySet) { System.out.println("Key: " + entry.getKey() + ", Value: " + entry.getValue());}
这将许可您迭代访问HashMap中的键值对。
同步HashMap 如果须要在多个线程之间共享HashMap,并且希望确保线程安全性,可以利用Collections.synchronizedMap方法创建同步的HashMap:Map<String, Integer> synchronizedHashMap = Collections.synchronizedMap(hashMap);
这将返回一个线程安全的HashMap。
获取键或值的凑集视图 如果须要获取HashMap中键或值的凑集视图,可以利用keySet和values方法。这些凑集视图是与原始HashMap关联的,对它们的变动将影响原始HashMap。打算HashMap的哈希码 要打算HashMap的哈希码,可以利用hashCode方法:int hashCode = hashMap.hashCode();
这将返回HashMap的哈希码值。
处理默认值 如果要从HashMap中获取值,如果键不存在,不仅返回默认值,还可以在键不存在时实行某个操作。您可以利用computeIfAbsent方法来实现这一点:hashMap.computeIfAbsent("orange", key -> { // 在键"orange"不存在时,实行此操作并返回默认值0 return 0;});
这将许可您在获取值的同时进行打算或其他操作。
4 把稳事变当利用HashMap时,有一些把稳事变须要考虑,以确保您的代码精确且高效地运行。以下是一些主要的把稳事变:
键的唯一性: HashMap中的键必须是唯一的。如果考试测验将相同的键插入HashMap中,新值将覆盖旧值。值可以重复: HashMap中的值可以重复。多个键可以映射到相同的值。空键: HashMap许可利用null作为键,但只能有一个null键。这意味着如果插入多个null键,后续的null键将覆盖前面的。并发性: HashMap不是线程安全的,如果在多个线程之间共享HashMap,请确保适当地同步访问,或者利用ConcurrentHashMap等线程安全的凑集。性能: HashMap的性能常日很好,但在某些情形下,可能会发生哈希冲突,导致性能低落。要优化性能,可以考虑调度HashMap的初始容量和负载因子。哈希函数: HashMap利用哈希函数将键映射到存储位置。如果键的哈希码分布不屈均,可能会导致哈希冲突。因此,确保自定义工具的hashCode方法精确实现,以得到更好的性能。遍历顺序: HashMap的遍历顺序不是按照插入顺序或任何特定顺序的。如果须要按特定顺序访问键值对,可以考虑利用LinkedHashMap。容量和负载因子: 考虑根据数据量选择适当的初始容量和负载因子。较大的初始容量可以减少哈希冲突,提高性能。空间繁芜度: HashMap的空间繁芜度是O(n),个中n是存储的键值对数量。因此,要谨慎利用大型HashMap,以避免内存占用过多。利用泛型: 在创建HashMap时,尽可能利用泛型来指定键和值的类型,以提高类型安全性。及时清理不再须要的键值对: 如果不再须要HashMap中的某个键值对,及时利用remove方法或其他办法删除它们,以开释内存和资源。非常处理: 当利用get方法获取值时,要考虑键不存在的情形,以避免NullPointerException。可以利用containsKey方法或条件语句来检讨键是否存在。性能监控: 如果HashMap用于性能关键的运用程序,考虑利用性能监控工具来剖析和优化HashMap的利用。备份: 定期备份HashMap中的主要数据,以防止数据丢失或破坏。














