
在mysql中,存储引擎用类似的方法利用索引,其现在索引中找到对应值,然后根据匹配的索引记录找到对应的数据行。加入运行下面的查询:
select username from system_user where user_id = 5;

如果在user_id列上建有索引,则Mysql将利用该索引找到user_id为5的行,也便是说,Mysql先在索引上按值查找,然后返回所有包含该值的数据行。
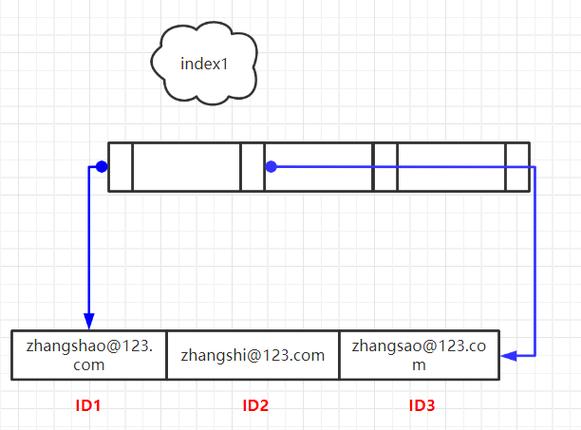
索引可以包含一个或多个列的值。如果索引包含多个列,那么列的顺序页十分主要,由于Mysql只能高效的利用索引的最左前缀列。创建一个包含两个列的索引,和创建两个只包含一列的索引是大不相同的。
索引类型
索引有多种类型,以适应不同的运用处景。Mysql中,索引是在存储引擎层而不是做事器层实现的。以是,没有统一的索引标准,不同引擎的索引事情办法并不一样,也不是所有的存储引擎都支持所有类型的索引。纵然多个存储引擎支持同一种类型的索引,其底层的实现也可能不同。
Mysql的索引类型有:B-Tree、哈希(hash index)、空间数据索引(R-Tree)、全文索引、其他索引(一些分外引擎利用)
B-Tree存储引擎以不同的办法利用B-Tree索引,性能也各有不同,各有利害。例如,MyISAM利用前缀压缩技能使得索引更小,但InnoDB则按照原数据格式进行存储。再如MyISAM索引通过数据的物理位置引用被索引的行,而InnoDB则根据主键引用被索引的行。
建立在B-Tree构造(从技能上来说是B+Tree)上的索引
B-Tree索引能够加快访问速率,由于存储引擎不再须要进行全表扫描获取须要的数据,取而代之的是从索引的根节点开始进行搜索。根节点的槽中存放了指向子节点的指针,存储引擎根据这些指针向下层查找。通过比较子节点页的值和要查找的值可以找到得当的指针进入下层子节点,这些指针实际上定义了子节点页中值的上限和下限。终极存储引擎要么是找到对应的值,要么该记录不存在。
B-Tree对索引列是顺序组织存储的,以是很适宜查找范围数据。
可以利用B-Tree索引的查询类型。B-Tree索引适用于全键值、键值范围或键前缀查找。个中键前缀查找只适用于根据最左前缀的查找。
全值匹配
全值匹配指的是和索引中的所有列进行匹配。
匹配最左前缀
只是用索引的第一列。
匹配列前缀
也可以只匹配某一列的值的开头部门。
匹配范围值
只是用索引的第一列。
精确匹配某一列并范围匹配其余一列
第一列的全匹配,第二列的列前缀匹配。
只访问索引的数据(覆盖索引)
B-Tree常日可以支持“只访问索引的查询”,即查询只须要访问索引,而无需访问数据行。
举例解释:
#创建索引ALTER TABLE `jr_person`ADD INDEX `name_mobile` (`name`, 'alias',`mobile`) USING BTREE;#全值匹配EXPLAIN SELECT from jr_person where alias = '维修工' and NAME = '刘国军' and mobile = '15837109838';实行结果+----+-------------+-----------+-------+---------------+-------------+---------+-------------+------+-------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |+----+-------------+-----------+-------+---------------+-------------+---------+-------------+------+-------+| 1 | SIMPLE | jr_person | const | name_mobile | name_mobile | 127 | const,const | 1 | |+----+-------------+-----------+-------+---------------+-------------+---------+-------------+------+-------+1 row in set (0.64 sec)#匹配最左前缀,即只是用索引第一列EXPLAIN SELECT from jr_person where NAME = '刘国军';实行结果+----+-------------+-----------+------+---------------+-------------+---------+-------+------+-------------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |+----+-------------+-----------+------+---------------+-------------+---------+-------+------+-------------+| 1 | SIMPLE | jr_person | ref | name_mobile | name_mobile | 82 | const | 1 | Using where |+----+-------------+-----------+------+---------------+-------------+---------+-------+------+-------------+1 row in set (0.00 sec)#匹配列前缀EXPLAIN SELECT from jr_person where name like '刘%';实行结果+----+-------------+-----------+-------+---------------+-------------+---------+------+------+-------------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |+----+-------------+-----------+-------+---------------+-------------+---------+------+------+-------------+| 1 | SIMPLE | jr_person | range | name_mobile | name_mobile | 82 | NULL | 216 | Using where |+----+-------------+-----------+-------+---------------+-------------+---------+------+------+-------------+1 row in set (0.00 sec)#匹配范围值EXPLAIN SELECT from jr_person where name BETWEEN '刘' and '张';实行结果+----+-------------+-----------+-------+---------------+-------------+---------+------+------+-------------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |+----+-------------+-----------+-------+---------------+-------------+---------+------+------+-------------+| 1 | SIMPLE | jr_person | range | name_mobile | name_mobile | 82 | NULL | 776 | Using where |+----+-------------+-----------+-------+---------------+-------------+---------+------+------+-------------+1 row in set (0.04 sec)#精确匹配某一列并范围匹配其余一列EXPLAIN SELECT from jr_person where NAME = '刘国军' and alias like '维%';+----+-------------+-----------+------+---------------+-------------+---------+-------+------+-------------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |+----+-------------+-----------+------+---------------+-------------+---------+-------+------+-------------+| 1 | SIMPLE | jr_person | ref | name_mobile | name_mobile | 82 | const | 1 | Using where |+----+-------------+-----------+------+---------------+-------------+---------+-------+------+-------------+1 row in set (0.00 sec)#只访问索引的查询EXPLAIN SELECT name,alias,mobile from jr_person where alias = '维修工' and NAME = '刘国军' and mobile = '15837109838';实行结果+----+-------------+-----------+-------+---------------+-------------+---------+-------------+------+-------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |+----+-------------+-----------+-------+---------------+-------------+---------+-------------+------+-------+| 1 | SIMPLE | jr_person | const | name_mobile | name_mobile | 127 | const,const | 1 | |+----+-------------+-----------+-------+---------------+-------------+---------+-------------+------+-------+1 row in set (0.00 sec)
关于Explan各个字段的先容参考这篇博文:Explain命令详解
哈希索引哈希索引(hash index)基于哈希表实现,只有精确匹配索引所有列的查询才有效。存储的每一行数据,存储引擎对所有的索引列打算一个哈希码(hash code);哈希索引将所有的哈希码储存在索引中,同时在哈希表中保存指向每个数据行的指针。
由于索引本身只存储哈希值,以是索引的构造十分紧凑,这让哈希索引查找速率变得非常快的同时,也产生了一些限定:
1、哈希索引只包含哈希值和行指针,而不存储字段,以是不能利用中银中的值来避免读取行(覆盖索引)。不过,访问内存中的行的速率非常快,以是大部分情形下这一点对应能的影响并不明显。
2、哈希索引数据并不是按照索引值顺序存储的,以是也就无法用于排序。
3、哈希索引不支持部分索引列匹配查找,由于哈希索引始终是利用索引列的全部内容来打算哈希值的。例如,在数据列(A,B)上建立哈希索引,如果查询只有数据列A,则无法利用该索引。
4、哈希索引只支持等值比较查询,包括=,in(),<=>(至于<=> 和<> 是不同的操作,<=>与=类似差异在于null值的判断)
5、访问哈希索引的数据非常快,除非有很多哈希冲突(不同的索引列值却有相同的哈希值),当涌现哈希冲突的时候,存储引擎必须遍历链表中所有的行指针,逐行进行比较,知道赵丹所有符合条件的行。
6、如果哈希冲突很多的话,一些索引掩护操作的代价也会很高。例如,如果在某个选择性很低(哈希冲突很多)的列上建立哈希索引,那么当从表中删除一行时,存储引擎须要遍历对应哈希链表中的每一行,找到并删除对应行的引用,冲突越多,代价越大。
由于以上各类限定,哈希索引只适用于某些特定场合。而一旦适宜哈希索引,则他带来的性能提升将非常显著。
InnoDB引擎不支持hash索引,但是他有一个分外的功能叫做“自适应哈希索引(adaptive hash index)”。当InnoDb把稳到某些索引值被利用的非常频繁时,他会在内存中基于B-Tree索引之上再建立一个哈希索引,这样就让B-Tree索引也具有哈希索引的一些优点,比如快速的哈希查找。这是一个完备自动的、内部的行为,用户无法掌握或者配置,不过如果有比较,完备可以关闭该功能。
创建自定义哈希索引。如果存储引擎不支持哈希索引,则可以仿照像InnoDB一样创建hash索引,这可以享受一些哈希索引的遍历,例如只须要很小的索引就可以为超长的建创建索引。
详细思路:在B-Tree根本上创建一个伪哈希索引。这和真正的哈希索引不是一回事,由于还是利用B-Tree进行查找,但是它利用哈希值而不是键值本身进行查找。你须要做的便是在查询的Where子句中手动指定利用的哈希函数。
下边是一个实例,例如要存储大量的URL,并须要根据URL进行搜索查找。如果利用B-Tree来存储URL,存储的内容就会很打,由于URL本身都很长。正常情形下会有如下查询:
select id from url where url = "http://www.phpblog.cn";
若删除原来URL列上的索引,而新增一个被索引的url_crc列,利用CRC32做哈希,就一颗利用下面的办法查询:
select id from url where url = "http:'//www.phpblog.cn" and url_crc = CRC32("http://www.phpblog.cn")
这样做性能会很高,由于mysql优化器会利用这个选择性很高而体积很小的基于url_crc列的索引来完成查找。纵然有多个记录有相同的索引值,查找仍旧很快,只须要根据哈希值做快速的整数比较就能找到索引条款,然后逐一比较返回对应的行。其余一种办法便是对完全的URL字符串做索引,那样会非常慢。
这样实现的毛病是须要掩护哈希值。可以手动掩护,也可以用触发器实现。
如果利用这种办法,记住不要利用md5()和SHA1()作为哈希函数。由于这两个函数打算出来的哈希值是非常长的的字符串,会摧残浪费蹂躏大量的空间,比较时也会更慢。SHA1()和MD5()是强加密函数,设计目标是最大限度肃清冲突,但这里并不须要这样高的哀求。大略哈希函数的冲突在一个可以接管的范围,同时又能够供应更好的性能。
如果数据表非常大,CRC32()会涌现大量的哈希冲突,则可以考虑自己实现一个大略的64位哈希函数。这个自定义函数要返回整数,而不是字符串。一个大略的方法可以利用MD5()函数返回值的一部分作为自定义哈希函数。这可能比自己写一个哈希算法的性能要差,不过这样实现最大略:
select conv(right(md5('http://www.phpblog.cn'),16),16,10) as HASH64;
CONV 可以转变目标数据的进制,上边的案例将md5的后16位,从16进制转换成10进制数字。
索引的优点
索引可以让做事器(数据库做事器)快读地定位到表的制订位置。但这并不是索引的唯一浸染,到目前为止可以看到,根据创建索引的数据构造不同,索引也有一些其他的附加浸染。
最常见的B-Tree索引,由于是按顺序存储数据,以是MySQL可以用作ORDER BY和GROUP BY操作。由于数据是有序的,以是B-Tree也就会将干系的列值存储在一起。末了,由于索引中存储了实际的值,以是某些查询只利用索引就能够完玉成体查询。根据此特性,总结下来索引有如下三个优点:
索引大大减少了做事器须要扫描的数据量。索引可以帮助做事器避免排序和临时表。索引可以将随机I/O变为顺序I/O。索引是最好的办理方案吗?
做引并不总是最好的工具。总的来说,只有当索引帮助存储引擎快速查找到记录带来的好处大于其带来的额外事情时,索引才是有效的。对付非常小的表,大部分情形下大略的全表扫描更高效。对付中到大型的表,索引就非常有效。但对付特大型的表建立和利用索引的代价将随之增长。这种情形下,则须要一种技能可以直接区分出查询须要的一组数据,而不是一条记录一条记录的匹配。比如可以利用分区技能。















